本文共 5392 字,大约阅读时间需要 17 分钟。
k8s是容器编排工具 大体的组件 1.master (需要把各种kv数据存储在etcd,分布式键值存储中,raft协议,集群式奇数节点,确保发生网络分区时能够确定谁拥有cron谁没有,防止脑裂)有三个重要的进程: APIserver与外部客户端请求的总接口,对于整个集群的控制管理使用都需要通过api,命令行工具是kubectl。假如需要在pod启动容器, 经由scheduler调度器,决定将这个请求发到哪个节点,调度的结果告诉给apiserver, 在每个node上有一个代表k8s工作的进程,称为kubelet,负责执行完成要在本地完成的任务,比如启动一个pod(在pod中启动一个container) controller-manager 监控编排的目标容器,防止要求启动的数量不够,是否符合我们指定的数量,在master进程监控和维护node节点,没启动就会帮你启动起来 kubelet在本地启动一个又一个pod,在pod内部可能又一个或多个容器,(pod应该有一个基础容器,infonce,container,作用是创建网络名称空间,让其他加入到此pod的容器,加入到网络名称空间,地址对于k8s来讲是属于pod的,一个pod有n个容器,n个容器共享同一个pod地址,同一组应用的pod可以启动不止一个,多个pod,同一应用的可以实现负载均衡的效果,既能冗余,又能实现负载均衡), 用户的请求就可以分发给两个pod, 对pod来讲,随着节点改变,有可能pod会中止 controller-manager要 确保每个pod有足够的量,因此有可能在其他node上启动另外的pod, 对k8s,内部每个节点的地址分配方式是平面化的,是可路由的ip,意味着可以尝试分一个B类网络网段,假设给一个所谓的集群,而后每一个节点可以得到一个子网,找个节点上的容器都应该分配子网中的地址 随意有可能启动的pod,地址已经发生改变了,由于pod地址经常发生改变,客户端如果直接访问pod,用ip地址访问,的得不到一个可持续访问的接口 容器运行一个dns服务,给每一个节点取一个主机名,访问时基于找个主机名来访问,前提是,pod地址改变了就需要改dns中的结果,这样子基于客户端访问得到的解析结果才是正确的, 需要及时更新,就需要一个联动的应用来实现,skydns。1。3之前,之后是kubedns,来完成找个功能,这个名称分配的结果只能是k8s内部节点的名称,而不是公网上解析的名称 而且这个名称的工作方式,主要是实现名称发现的,服务注册和名称发现的,生来的目的就是来解决这方面的问题, kubedns对k8s是一个addon附件,不是一个插件,用不用是取决于你,对k8s来讲有个组件,能 够将地址固定化, 基于falnnel,来地址分配的时候,k8s自己有一个约定俗称的方式,把10.254.0.0这个地址段内的, 预留给service 构建出一个service的逻辑组件来,这个组件拥有一个固定地址,地址是从这个地址段分配出来的,分配出来就固定的,动态分配但不回收,创建一个服务组件以后来给个地址,外部用户访问这个地址的时候,客户端是一直固定不变的,他只是将用户的请求代理至关联到的后端容器,反代也需要知道地址,反代服务器如何知道节点在哪里,服务反代不是基于地址来关联到pod的,而是label,基于标签的方式关联到各pod,标签就是键值对的组合,如果两个pod标签相同,不管地址是什么,service都能帮你挑出来 每一个node都有一个组件kubeproxy,是每一个service的实现,service是一个逻辑组件,真正实现反代功能的组件 pod在本机可能不止一个,kubeproxy调度的可能pod也不止一个,而kube proxy早些时候,是一个主机上的网路名称空间,这个名称空间可以生成,所谓的iptables规则(dnat),后来,通过iptables可以把用户的请求负载均衡到本地节点不同的pod上 , service ,label,kube_proxy,kubelet。 apiserver scheduler controller-manager kubectl etcd-manager
k8s集群详细架构图
 用这些对象来表现集群中个组件的状态
用这些对象来表现集群中个组件的状态 这些状态包含这么几条
这些状态包含这么几条 用描述式的语言来表示在k8s集群当中,在每个节点上运行容器上的应用程序,那个pod运行什么容器,要用k8s所谓的对象来进行表示
用描述式的语言来表示在k8s集群当中,在每个节点上运行容器上的应用程序,那个pod运行什么容器,要用k8s所谓的对象来进行表示
可得到的资源有哪些
 对容器化的应用程序来讲,如何去定义本身的策略,升级是滚动升级还是一起升级
对容器化的应用程序来讲,如何去定义本身的策略,升级是滚动升级还是一起升级 
 每一个集群对象就是 record of intent,对象创建以后,k8s集群必须保持存在,如果意外宕机,k8s集群会继续尝试帮他创建出一个,k8s集群式必须确保对象存在的改变 所以在创建对象的时候,必须告诉k8s集群,这个对象应该处于什么状态,应该附有什么样的工作方式,这种称为集群期望的目标状态 desired state,(类似puppet部属应用的时候,需要描述目标状态,确保每个资源处于应该处的状态) 对k8s来讲,调度的不是资源而叫k8s对象,这个k8s对象核心的就是容器或者称为pod,对于k8s集群的管控,要通过k8s的API来进行,master镜像的APIserver 对整个k8s的集群对象管理,只有通过k8sapi的来实现,apiserver
每一个集群对象就是 record of intent,对象创建以后,k8s集群必须保持存在,如果意外宕机,k8s集群会继续尝试帮他创建出一个,k8s集群式必须确保对象存在的改变 所以在创建对象的时候,必须告诉k8s集群,这个对象应该处于什么状态,应该附有什么样的工作方式,这种称为集群期望的目标状态 desired state,(类似puppet部属应用的时候,需要描述目标状态,确保每个资源处于应该处的状态) 对k8s来讲,调度的不是资源而叫k8s对象,这个k8s对象核心的就是容器或者称为pod,对于k8s集群的管控,要通过k8s的API来进行,master镜像的APIserver 对整个k8s的集群对象管理,只有通过k8sapi的来实现,apiserver 对象的两个核心属性,每一个k8s对象,都要包含两个彼此有可能嵌套的对象字段,对象属性,主要式来管理对象的配置, 1.spec() 2.status(类似puppet目标指明某个主机的tomcat必须为不安装状态,但是当下状态可能是运行的,所以每个资源有当前状态和目标状态)
对象的两个核心属性,每一个k8s对象,都要包含两个彼此有可能嵌套的对象字段,对象属性,主要式来管理对象的配置, 1.spec() 2.status(类似puppet目标指明某个主机的tomcat必须为不安装状态,但是当下状态可能是运行的,所以每个资源有当前状态和目标状态) spec期望的状态
 status当前状态
status当前状态  这就是k8s集群的spec和status,如何去定义k8s集群就是一个又一个的container, 1.有几个副本 2。应该处于什么目标状态
这就是k8s集群的spec和status,如何去定义k8s集群就是一个又一个的container, 1.有几个副本 2。应该处于什么目标状态 任何给定的时间,k8s的控制面板,负责去管理每一个对象要处于目标状态 (类似puppet,但是puppet管理的是资源,k8s管理的叫对象)

 编排一组容器有replicasets,controller, deployment(官方推荐的容器编排方式) deployment实例
编排一组容器有replicasets,controller, deployment(官方推荐的容器编排方式) deployment实例 yaml格式的 api版本是什么,不同k8ss的版本兼容的api版本也不同,程序升级了,内部的api也有可能会升级,所以必须描述清楚当前此文件所适用的api版本,字符并不区分大小写
yaml格式的 api版本是什么,不同k8ss的版本兼容的api版本也不同,程序升级了,内部的api也有可能会升级,所以必须描述清楚当前此文件所适用的api版本,字符并不区分大小写  用来指明当前对应的部署,应该属于哪一种对应的部署方式,kind:deployment
用来指明当前对应的部署,应该属于哪一种对应的部署方式,kind:deployment  元数据,作为unique key of the deployment instance,每一个deployment在k8s中 是一个实例,deployment实例。 deployment创建,是完全可以实现把它删除的,因此将来完成创建,还要回过来引用这个部署,对此部署,可以根据自己的需求来删除,升级 引用的符号就是deployment名称,一般约定俗成,文件名是什么,deployment就是什么
元数据,作为unique key of the deployment instance,每一个deployment在k8s中 是一个实例,deployment实例。 deployment创建,是完全可以实现把它删除的,因此将来完成创建,还要回过来引用这个部署,对此部署,可以根据自己的需求来删除,升级 引用的符号就是deployment名称,一般约定俗成,文件名是什么,deployment就是什么  描述其目标状态, 1.replicas副本数量,启动多少个pod,多了关掉,少了补足 2.template pod自身模版 3.label kv=app键:nginx值 ,这一组pod都会有相同的label 让label基于所谓的selecor挑选以后定义成service,只要有一个label就属于一个service
描述其目标状态, 1.replicas副本数量,启动多少个pod,多了关掉,少了补足 2.template pod自身模版 3.label kv=app键:nginx值 ,这一组pod都会有相同的label 让label基于所谓的selecor挑选以后定义成service,只要有一个label就属于一个service 第一个spec是描述pod的目标状态,每个pod是用来运行容器的 下面是嵌套的spec 缩进,每个pod用来运行的容器、 列表容器,在每个pod内部的容器至少有一个 name容器名字=nginx 是作为dns_label使用的 image 基于哪个镜像来启动容器的 每个pod内部有一个容器nginx 每个pod都有一个标签,app:nginx
第一个spec是描述pod的目标状态,每个pod是用来运行容器的 下面是嵌套的spec 缩进,每个pod用来运行的容器、 列表容器,在每个pod内部的容器至少有一个 name容器名字=nginx 是作为dns_label使用的 image 基于哪个镜像来启动容器的 每个pod内部有一个容器nginx 每个pod都有一个标签,app:nginx 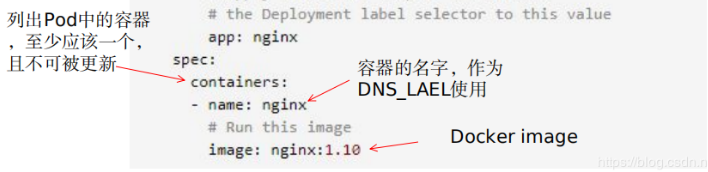 一般deployment对象要么是pod,要么是service 创建好一个deployment’要记录下来
一般deployment对象要么是pod,要么是service 创建好一个deployment’要记录下来 对应的每个yaml格式的文件中,三个组件是必须的 apiversion kind metadata
对应的每个yaml格式的文件中,三个组件是必须的 apiversion kind metadata https://kubernetes.io/docs/resources-reference/v1.5
https://kubernetes.io/docs/resources-reference/v1.5 replicas对应应该启动pod的数量
replicas对应应该启动pod的数量 template创建pod时,要用到的模板
template创建pod时,要用到的模板 pod模板属性有俩个属性, metadata, spec
pod模板属性有俩个属性, metadata, spec pod自身的属性
pod自身的属性
 暴露出哪些端口
暴露出哪些端口 可用使用container而不使用pod来直接运行一个容器
可用使用container而不使用pod来直接运行一个容器 定义的pod
定义的pod 可用使用deployment来编排一个完整意义上的容器
可用使用deployment来编排一个完整意义上的容器 也可用使用daemon set来编排使用容器
也可用使用daemon set来编排使用容器 推荐使用deployment
推荐使用deployment service对象,基于name可以删除和修改unique key要唯一 targetport目标端口80、 每个service在kube 更像是dnat,service就是一个静态ip,pod哪个容器监听80就转给哪个容器 service重要的组件selector,把哪些label归类到此service上来 service定义好了,需要有pod,不然用户请求来了,不知道转发到哪里 type:loadbalancer 负载均衡,调度到哪个pod的容器上

 能过够被别人做dnat目标转发的端口
能过够被别人做dnat目标转发的端口 selector,发往此service的流量,转发到pod
selector,发往此service的流量,转发到pod 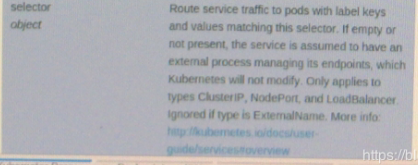 type,请求到达ip地址以后,转发其道后端pod之上的方式 可用的选项有externalname对外的名称 clusterip,nodeport,loadbalance直接负载均衡调度
type,请求到达ip地址以后,转发其道后端pod之上的方式 可用的选项有externalname对外的名称 clusterip,nodeport,loadbalance直接负载均衡调度 cluster的ip,发给另外的service,由service调用下一个service,用的比较多的可能就是loadbalance
cluster的ip,发给另外的service,由service调用下一个service,用的比较多的可能就是loadbalance
**部署k8s首先部署的是etcd,所以先启动etcd,2379,2380端口
先启动flannel 启动master节点,三个服务 apiserver,controller-manager,kube-scheduler ** node2,1节点都启动服务
node2,1节点都启动服务  使用ifcofnig,查看docker0应该是使用的,flannel分配的地址,重新启动以后地址可能要重新分配的
使用ifcofnig,查看docker0应该是使用的,flannel分配的地址,重新启动以后地址可能要重新分配的 kubectl可用访问集群
kubectl可用访问集群  对应各种接口的version版本
对应各种接口的version版本 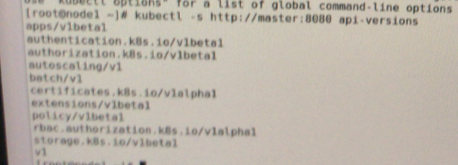 定义一个deployment来启动容器 定义一个启动httpd 的镜像
定义一个deployment来启动容器 定义一个启动httpd 的镜像

 mantainer 维护者 add 添加文件 把app/data当作默认运行的使用目录 cmd 运行程序,传递参数-f运行前台,-h家目录 appdata expose暴露端口
mantainer 维护者 add 添加文件 把app/data当作默认运行的使用目录 cmd 运行程序,传递参数-f运行前台,-h家目录 appdata expose暴露端口  构建镜像,打标签,不适用执行
构建镜像,打标签,不适用执行 使用下面的
使用下面的  推镜像上去,不使用执行
推镜像上去,不使用执行 另外的节点去pull下来,不使用执行
另外的节点去pull下来,不使用执行 先手动启动镜像看看,使用这个
先手动启动镜像看看,使用这个
 访问没有问题就关闭
访问没有问题就关闭 把这个镜像推上去
把这个镜像推上去 另外的节点pull下来
另外的节点pull下来 定义一个deployment replicas启动几个副本 保存过去的版本revisionhistorylimit,方便回滚 container是spec所有的属性,需要缩进
定义一个deployment replicas启动几个副本 保存过去的版本revisionhistorylimit,方便回滚 container是spec所有的属性,需要缩进 
 跑一边试试,-f指明哪个文件来create
跑一边试试,-f指明哪个文件来create 查看信息,期望由两个副本,现在是2各副本
查看信息,期望由两个副本,现在是2各副本 调度到node1,2上了
调度到node1,2上了 所以在node1,2各自可用看到pod
所以在node1,2各自可用看到pod 没起来,下载文件失败,即便本地有也会向服务器拖
没起来,下载文件失败,即便本地有也会向服务器拖 删除刚才的deployment,意味刚才创建的pod信息都没有了,重新修改文件
删除刚才的deployment,意味刚才创建的pod信息都没有了,重新修改文件 **对方好像不允许使用本地仓库使用镜像的,推到dockerhub也可以,打新的标签推之前需要先登陆 **
**对方好像不允许使用本地仓库使用镜像的,推到dockerhub也可以,打新的标签推之前需要先登陆 **
 另外节点可以pull一份下来
另外节点可以pull一份下来

 再次创建
再次创建 启动起来了
启动起来了 端口没有做暴露,deployment定义时没有暴露
端口没有做暴露,deployment定义时没有暴露 查看这个容器
查看这个容器 没有暴露端口,是因为就k8s启动的,地址和端口属于pod不属于容器
没有暴露端口,是因为就k8s启动的,地址和端口属于pod不属于容器  pod启动成功
pod启动成功 要想能被访问需要定义一个service
要想能被访问需要定义一个service 转载地址:http://eckgn.baihongyu.com/